Thế hệ tăng cường truy xuất được cho là sẽ tăng cường các mô hình ngôn ngữ lớn với kiến thức bên ngoài. Nó có thể hoạt động rất tốt trong các bản demo:một tập dữ liệu nhỏ được tuyển chọn, các truy vấn rõ ràng và ngân sách độ trễ không bị giới hạn dẫn đến các câu trả lời có căn cứ, hiểu biết mà người dùng tin là đúng. Tuy nhiên, nhiều nhóm nhận thấy rằng một khi họ triển khai ứng dụng RAG cho người dùng, hiệu suất sẽ giảm sút. Các truy vấn trở nên mơ hồ, kho dữ liệu mở rộng, chất lượng truy xuất giảm xuống, độ trễ tăng cao và hệ thống âm thầm bắt đầu giảm độ chính xác. Tệ hơn nữa, các kỹ thuật đánh giá kém sẽ ẩn giấu chỗ hệ thống thực sự bắt đầu gặp lỗi cho đến khi người dùng phàn nàn. Bài viết này tìm hiểu lý do tại sao nhiều hệ thống RAG không thành công trong quá trình sản xuất. Chúng tôi rút ra từ những nghiên cứu gần đây và hướng dẫn của ngành. Chúng tôi đóng khung các vấn đề xung quanh chất lượng truy xuất, sự cân bằng về độ trễ, độ lệch nhúng và khoảng trống đánh giá dưới dạng các liên kết trong một chuỗi các chế độ lỗi. Mỗi liên kết trong chuỗi này phải được tính toán để xây dựng một hệ thống RAG sản xuất mạnh mẽ.
Bài học chính
- Hầu hết các lỗi RAG đều bắt đầu ở quá trình truy xuất chứ không phải ở quá trình tạo. Khi hệ thống truy xuất bằng chứng không đầy đủ, không liên quan hoặc được xếp hạng kém, ngay cả LLM mạnh cũng sẽ đưa ra câu trả lời yếu.
- Truy xuất tốt hơn đòi hỏi phải có những lựa chọn kỹ thuật tốt hơn. Phân đoạn nhận biết miền, truy xuất kết hợp và sắp xếp lại được trình bày dưới dạng các kỹ thuật cốt lõi nhằm cải thiện mức độ liên quan và giảm thiểu các lỗi truy xuất thầm lặng.
- Độ trễ nhanh chóng trở thành nút thắt trong sản xuất. Việc thêm top_k lớn hơn, trình xếp hạng lại, ngữ cảnh dài và các bước truy xuất bổ sung có thể cải thiện khả năng ghi nhớ nhưng cũng có thể khiến hệ thống trở nên quá chậm đối với người dùng thực.
- Việc nhúng trôi dạt sẽ âm thầm làm giảm hiệu suất theo thời gian. Những thay đổi trong mô hình nhúng, bộ sưu tập tài liệu và từ vựng của người dùng đều có thể thay đổi hành vi truy xuất, vì vậy việc lập phiên bản và khả năng quan sát là cần thiết.
- Chỉ chất lượng câu trả lời cuối cùng thôi là chưa đủ để đánh giá. Các nhóm cần có số liệu truy xuất và tạo riêng biệt, bộ thử nghiệm thực tế, giám sát liên tục và khả năng hệ thống tránh khi bằng chứng yếu hoặc thiếu.
Thất bại do chất lượng truy xuất kém
Chất lượng truy xuất thấp là một trong những nguyên nhân thường gặp nhất gây ra lỗi hệ thống RAG khi triển khai vào sản xuất. Các nhà phát triển thường đổ lỗi cho LLM về những câu trả lời sai/xấu; tuy nhiên, lỗi thường nằm sớm hơn trong đường ống. Nếu hệ thống không thể truy xuất bằng chứng đầy đủ hoặc có liên quan hoặc xếp hạng bằng chứng kém thì ngay cả mô hình tốt nhất cũng khó có thể tạo ra phản hồi đáng tin cậy. Chất lượng truy xuất phải được coi là mối quan tâm kỹ thuật hàng đầu chứ không phải là bước cơ bản.
Hầu hết các lỗi xảy ra trước khi LLM nhìn thấy truy vấn
Quy trình tiêu chuẩn nhúng truy vấn của người dùng, truy xuất các tài liệu top-k từ kho lưu trữ vectơ và gửi chúng tới LLM. Mỗi mũi tên trong đường dẫn đó đều có thể là một điểm thất bại.
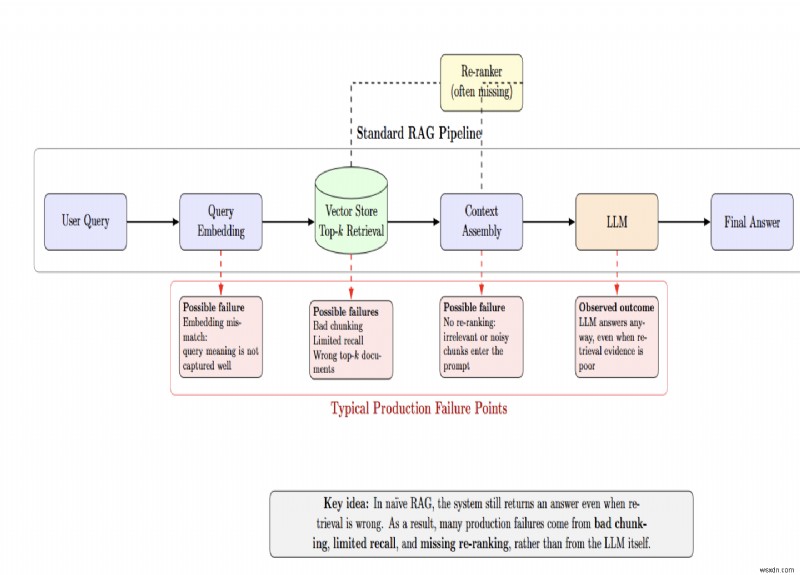
RAG ngây thơ che giấu những lỗi này vì hệ thống cung cấp câu trả lời bất kể việc truy xuất có sai hay không. Nhiều vấn đề về sản xuất phát sinh từ các chiến lược phân chia không hợp lý, hạn chế thu hồi và thiếu sắp xếp lại, chứ không phải do những thiếu sót của LLM.
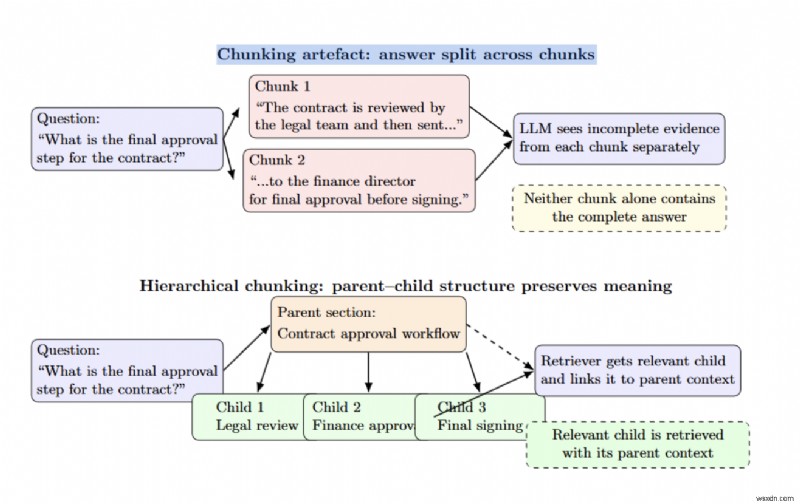
Việc chia nhỏ sai lầm tạo ra những thất bại thầm lặng
Kích thước khối tác động đến độ chính xác/thu hồi - khối lớn hơn cung cấp nhiều ngữ cảnh hơn với ít mức độ liên quan hơn, trong khi khối nhỏ hơn mang lại độ chính xác cao hơn nhưng làm mất thông tin xung quanh. Phân đoạn phân cấp (mẹ-con) giải quyết sự cân bằng này bằng cách lưu trữ toàn bộ các phần dưới dạng đoạn gốc và chỉ truy xuất đoạn con nhỏ hơn có liên quan.
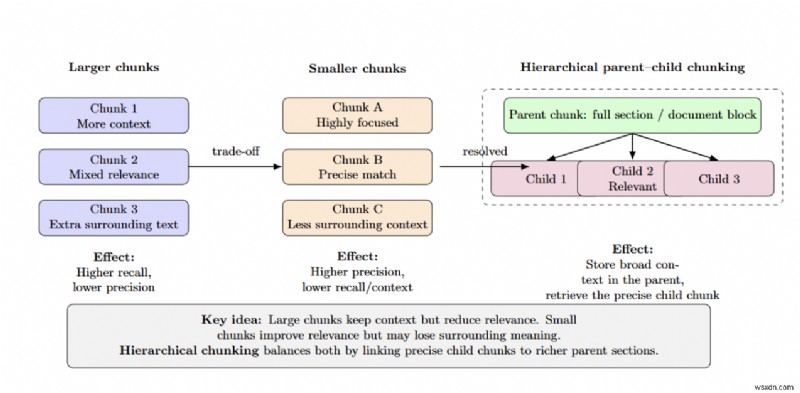
Thử nghiệm nội bộ của NVIDIA trên các bản trình bày của trường đại học cho thấy việc phân chia theo cấp bậc cải thiện độ chính xác của câu trả lời từ 61% với các đoạn có kích thước cố định lên 89%. Điều quan trọng là chọn kích thước khối thích hợp trong khi vẫn tôn trọng ranh giới cấu trúc và áp dụng phân tách nhận biết miền nếu có thể.
Truy xuất kết hợp và sắp xếp lại
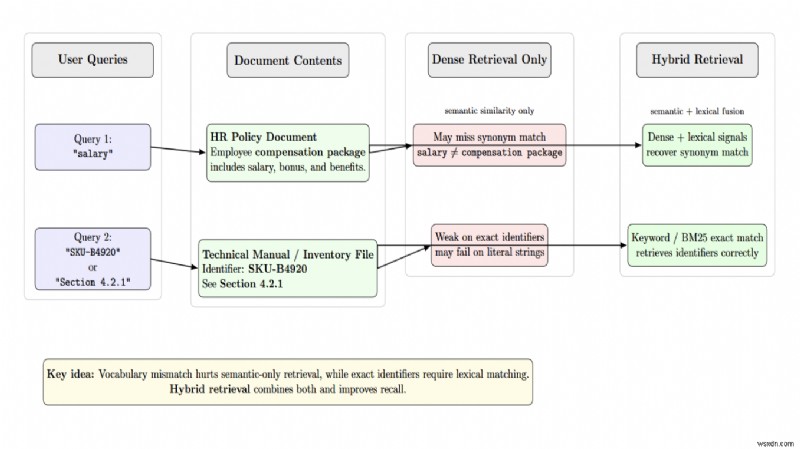
Truy xuất dày đặc thuần túy có khả năng tương tự về mặt ngữ nghĩa nhưng bỏ lỡ các định danh chính xác. Tìm kiếm từ khóa thuần túy rất nhạy cảm với các thuật ngữ chính xác nhưng lại thất bại trong việc diễn giải ngữ nghĩa. Các hệ thống truy xuất kết hợp chạy truy xuất dày đặc (vectơ) và truy xuất thưa thớt (BM25/từ khóa) đồng thời, sau đó kết hợp các kết quả của chúng với sự kết hợp thứ hạng đối ứng.
Các hệ thống truy xuất kết hợp giải quyết sự không khớp từ vựng bằng cách kết hợp các tín hiệu tương tự về ngữ nghĩa với các tín hiệu khớp từ vựng. Việc tính điểm lại các cặp ứng cử viên bằng bộ xếp hạng lại (bộ mã hóa chéo) sau khi hợp nhất sẽ cải thiện khả năng thu hồi. Về cơ bản, người sắp xếp lại sắp xếp lại các tài liệu được truy xuất để chỉ những tài liệu phù hợp nhất mới được đưa vào bối cảnh mà LLM xem xét. Điều này giúp tiết kiệm giới hạn mã thông báo và tránh nhồi nhét ngữ cảnh trong khi cải thiện khả năng truy xuất LLM.
Số liệu truy xuất phải được giám sát riêng
Các nhóm có xu hướng chỉ đo lường chất lượng câu trả lời từ đầu đến cuối. Bản thân quá trình truy xuất có các số liệu mà bạn có thể sử dụng:Precision@k (tỷ lệ nào trong số các khối được truy xuất có liên quan? ),recall@k (bạn đã truy xuất được bao nhiêu phần của các khối có liên quan? ), xếp hạng tương hỗ trung bình (khối có liên quan đầu tiên cao đến mức nào? ) và mức tăng tích lũy được chiết khấu chuẩn hóa (xếp hạng tổng thể của bạn tốt đến mức nào?).

Nếu bạn không đo lường những điều này, bạn sẽ không biết liệu lỗi là do truy xuất kém hay do trình tạo không tốt. Truy vấn kiểm tra và bộ dữ liệu vàng sẽ cho phép bạn đánh giá ngoại tuyến. Nếu theo dõi các chỉ số này trên các truy vấn thực, bạn có thể hiển thị kết quả hồi quy sản xuất.
Chẩn đoán lỗi truy xuất bằng các ví dụ
Các truy vấn mơ hồ và từ vựng không khớp thường dẫn đến việc truy xuất không chính xác. Người dùng có thể tìm kiếm “tiền lương” trong khi tài liệu đề cập đến “gói bồi thường”. Các phần nhúng dày đặc có thể không nhận ra được từ đồng nghĩa, trong khi truy xuất kết hợp sẽ khắc phục điều này. Một trường hợp khác là đối với các kết quả khớp chính xác, chẳng hạn như số nhận dạng. Truy vấn cho “SKU‑B4920” hoặc “Mục 4.2.1” cần khớp từ vựng chính xác.
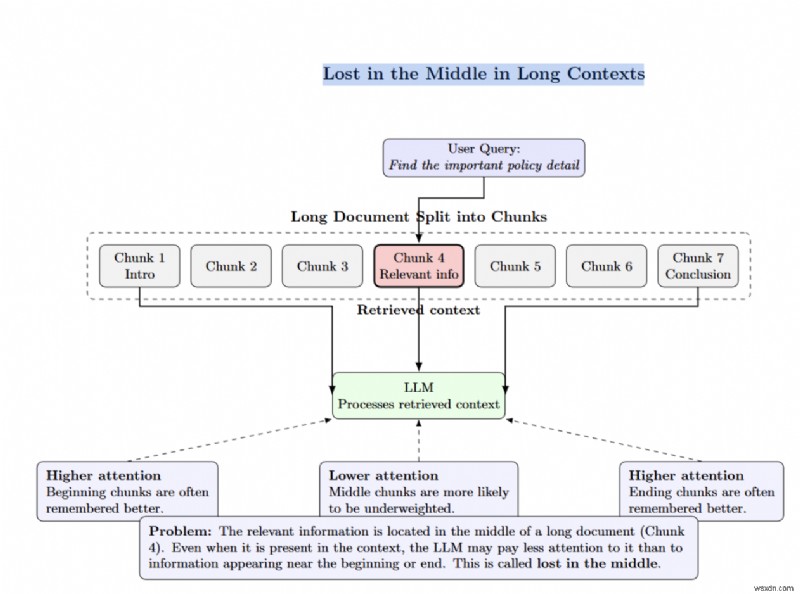
“Lạc giữa chừng” xảy ra khi thông tin liên quan bị chôn sâu trong một tài liệu dài dòng. LLM sẽ giảm trọng lượng token ở phần giữa.
Các đồ tạo tác phân đoạn phát sinh khi một câu trả lời được chia thành hai phần, vì vậy không có phần nào chứa câu trả lời hoàn chỉnh. Phân chia theo cấp bậc giúp giảm thiểu điều này bằng cách kết nối các nút cha và nút con.
Thất bại do độ trễ bùng nổ trong hệ thống thực
Độ trễ là một trong những lý do chính khiến hệ thống RAG hoạt động trong bản demo gặp khó khăn trong quá trình sản xuất. Khi quy trình truy xuất trở nên phức tạp hơn, thời gian phản hồi có thể tăng lên nhanh chóng và buộc các nhóm phải đánh đổi chất lượng câu trả lời để lấy khả năng sử dụng.
Sự cân bằng giữa khả năng truy xuất và độ trễ
Đội ngũ sản xuất thường phải cân bằng giữa chất lượng truy xuất và ngân sách độ trễ của họ. Mọi thứ làm tăng thời gian phản hồi (mở rộng hơn với top_k, thêm truy xuất kết hợp, thực hiện sắp xếp lại hoặc chạy các mô hình ngữ cảnh dài) đều cắt giảm ngân sách đó. Sự cân bằng này đặc biệt khó khăn vì người dùng mong đợi các câu trả lời đáp ứng và việc tích hợp cho doanh nghiệp đi kèm với ngân sách có độ trễ cố định. Tuy nhiên, như nghiên cứu gần đây của Cornell và NVIDIA đã chứng minh, RAG phải gánh chịu chi phí về độ trễ đáng kể. Việc chạy truy xuất quá thường xuyên có thể tăng độ chính xác nhưng lại tăng độ trễ từ đầu đến cuối lên gần 30 giây—quá cao để sử dụng trong sản xuất.
Thế hệ thường chiếm ưu thế, nhưng việc thu hồi mới là vấn đề
Đo điểm chuẩn bằng RAGPerf cho thấy rằng việc tạo thường là phần chiếm ưu thế trong quy trình RAG chỉ có văn bản . Việc chọn LLM nhỏ hơn có thể giảm đáng kể độ trễ mà không làm giảm chất lượng câu trả lời nếu chất lượng truy xuất được duy trì. Quy trình đa phương thức (truy xuất PDF và hình ảnh) có nhu cầu tính toán lớn một phần do việc sắp xếp lại và các mô hình đa phương thức liên quan. Độ trễ truy xuất có thể tăng lên khi cơ sở dữ liệu vectơ chậm hoặc không cho phép tra cứu đồng thời. Tuy nhiên, ngay cả khi tra cứu nhanh, việc sắp xếp lại có thể chi phối tổng độ trễ đối với nhiều khối lượng công việc RAG.
Thời gian trễ, chi phí và ngữ cảnh
Một số nhóm cố gắng giải quyết việc thu hồi bằng cách tăng top_k hoặc nhồi nhét nhiều tài liệu hơn vào ngữ cảnh của LLM. Các nghiên cứu cho thấy điều này có tác dụng ngược lại. Bạn càng thêm nhiều tài liệu vào lời nhắc thì LLM càng ít có khả năng nhớ lại thông tin chính xác. Xếp hạng lại truy xuất giải quyết vấn đề này bằng cách truy xuất nhiều tài liệu, sau đó chỉ chọn những tài liệu tốt nhất cho LLM. Cửa sổ ngữ cảnh dài gây ra hiện tượng "lạc giữa chừng" và chi phí tính toán rất lớn.
Tối ưu hóa độ trễ
Việc giải quyết độ trễ trong hệ thống RAG đòi hỏi phải có sự điều phối có chủ ý trên toàn bộ quy trình:
Thất bại do sự trôi dạt và thay đổi kiến thức
Phần nhúng thể hiện văn bản dưới dạng vectơ nhiều chiều có ý nghĩa tương tự gần nhau. Các nhóm thường xuyên nhúng lại tài liệu của họ bằng một mô hình nhúng khác hoặc hoán đổi bộ mã hóa truy vấn mà không lập phiên bản chính xác cho chỉ mục của họ hoặc đo điểm chuẩn các thay đổi về mức độ liên quan. Mô hình mới có thể mạnh mẽ hơn về mặt khách quan, nhưng nó có thể thay đổi cấu trúc vùng lân cận theo những cách không ngờ tới, tác động đến xếp hạng, thu hồi hoặc thậm chí là ngôn ngữ dành riêng cho miền. Một mô hình vượt trội ở các điểm chuẩn tổng quát có thể hoạt động kém hiệu quả với biệt ngữ doanh nghiệp trong thế giới thực của bạn.
Ba nguyên nhân gây trôi dạt
- Mô hình trôi dạt. Các mẫu mã nhúng được cập nhật liên tục. Khi bạn lập chỉ mục các tài liệu bằng cách sử dụng phiên bản của mô hình nhúng, bạn không thể tìm kiếm chúng bằng các phần nhúng từ mô hình khác. Việc chuyển đổi mô hình nhúng mà không lập chỉ mục lại kho văn bản sẽ ảnh hưởng đến việc truy xuất của bạn.
- Sự trôi dạt của tử thi. Khi bạn thêm tài liệu mới vào chỉ mục, đặc biệt là các tài liệu thuộc loại mới, không gian vectơ sẽ thay đổi. Các cụm vectơ dày đặc mới xuất hiện. Các cụm dày đặc đó bắt đầu thu thập các truy vấn cần khớp với các tài liệu khác. Việc thêm nội dung do người dùng tạo hoặc gây nhiễu sẽ làm giảm chất lượng truy xuất theo thời gian, ngay cả khi bạn không thay đổi mô hình nhúng.
- Truy vấn trôi dạt. Vốn từ vựng của người dùng mở rộng và thay đổi theo thời gian. Các thuật ngữ mới được sử dụng (“làm việc từ xa”, “stablecoin”, “kỹ thuật nhanh chóng”) và thuật ngữ cũ không còn nữa. Các phần nhúng có sẵn không thể khớp với các từ không tồn tại khi chúng được đào tạo. Nếu một công ty thay đổi tên của một trong các sản phẩm của mình thì việc tìm kiếm tên mới sẽ không thành công vì các phần nhúng vẫn phản ánh tên cũ.
Phát hiện sự trôi dạt nhúng với xếp hạng đối ứng trung bình
Dưới đây là sơ đồ ví dụ minh họa cách phát hiện độ lệch nhúng bằng cách theo dõi những thay đổi về hiệu suất truy xuất trước và sau khi thay đổi hệ thống hoặc theo thời gian. Trước tiên, sơ đồ tính toán điểm MRR cơ bản trong đó các tài liệu liên quan xuất hiện ở gần đầu bảng xếp hạng. Sau đó, nó tính toán điểm MRR hiện tại trong đó các tài liệu liên quan được xếp hạng sâu hơn trong bảng xếp hạng. Sau đó, hệ thống tính toán phần trăm giảm giữa MRR cơ sở và MRR hiện tại. Nếu mức giảm MRR vượt quá ngưỡng đã chọn trước, hệ thống sẽ đưa ra cảnh báo về độ lệch nhúng và đề xuất xem xét mô hình nhúng, phân phối dữ liệu và chỉ mục. Ngược lại, nếu mức giảm dưới ngưỡng thì hệ thống sẽ xác định hệ thống truy xuất ổn định và tiếp tục giám sát.
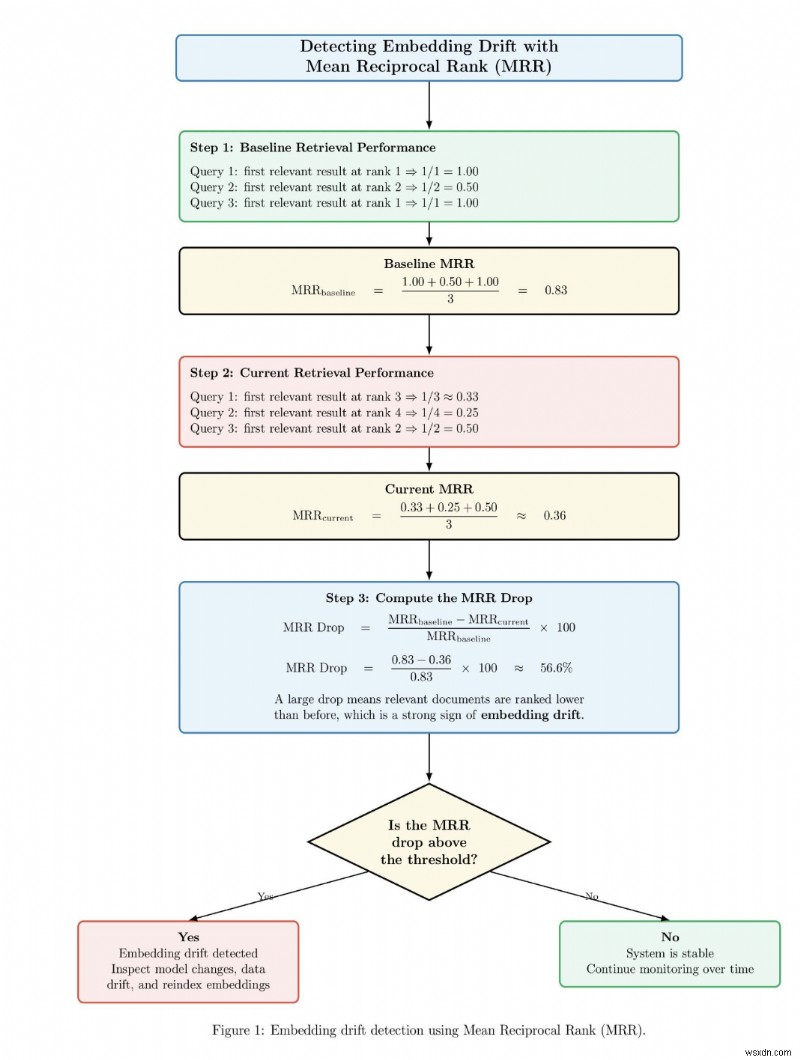
Vì lý do này, các hệ thống RAG sản xuất cần phải được phiên bản rõ ràng và có thể quan sát được. Các phần nhúng phải được phiên bản. Việc xây dựng chỉ mục phải có thể theo dõi được. Chính sách chunking nên được ghi lại và có thể tái tạo. Nếu chất lượng bắt đầu suy giảm, bạn phải trả lời được các câu hỏi như:Mô hình nhúng nào tạo ra chỉ mục này? Quy tắc phân đoạn nào đã tạo ra đoạn nội dung này? Lần cuối tài liệu này được nhập lại vào hệ thống là khi nào? Công cụ truy xuất và xếp hạng lại nào đã thực hiện yêu cầu này?
Nếu bạn không có tầm nhìn vào đường ống, sự trôi dạt sẽ có vẻ ngẫu nhiên. Với nó, nó có thể được chẩn đoán.
Thất bại do khoảng cách đánh giá:Che giấu nút thắt thực sự
Đánh giá yếu là lý do phổ biến thứ tư khiến các nhóm không triển khai hệ thống RAG vào sản xuất. Chúng ta có xu hướng chỉ đánh giá câu trả lời cuối cùng. Thế vẫn chưa đủ.
RAG cấp sản xuất là một đường dẫn. Ở bất kỳ số lớp nào, đầu vào kém có thể gây ra đầu ra cuối cùng kém. Người truy xuất có thể đã không truy xuất được đúng tài liệu. Người xếp hạng có thể đã xếp hạng bằng chứng tốt nhất quá thấp. Trình biên dịch ngữ cảnh có thể đã bao gồm quá nhiều tiếng ồn. Máy phát điện có thể đã che khuất lối đi mạnh nhất. Câu trả lời có thể đúng ở mức độ rộng nhưng vẫn hoàn toàn không trung thực với bằng chứng thu được. Bạn không thể xác định được các giai đoạn yếu nếu chỉ chấm điểm văn bản đầu ra cuối cùng.
Các số liệu truy xuất nên được đánh giá riêng
Vì lý do này, việc đánh giá RAG nên bao gồm các số đo truy xuất riêng biệt với các số liệu tạo. Số liệu truy xuất phải bao gồm độ chính xác của ngữ cảnh và thu hồi ngữ cảnh.
- Gợi nhớ bối cảnh :Việc thu hồi ngữ cảnh sẽ kiểm tra xem các đoạn văn được truy xuất có chứa thông tin cần thiết để trả lời câu hỏi hay không.
- Độ chính xác của bối cảnh :Độ chính xác của ngữ cảnh đo lường xem tập hợp được truy xuất có liên quan chủ yếu hay bị nhiễu.
- Chất lượng xếp hạng: Chất lượng xếp hạng cũng quan trọng vì một đoạn văn có liên quan ở hạng 1 sẽ hữu ích hơn đoạn văn có liên quan đó ở hạng 10.
Các chỉ số về thế hệ cũng quan trọng không kém
Sau khi đo lường quá trình truy xuất, lớp tạo phải được đánh giá theo các điều kiện riêng của nó. Hai thước đo chính là tính có cơ sở và tính trung thực.
- Tính căn bản: Tính căn cứ hỏi liệu câu trả lời có phản ánh thông tin được cung cấp trong ngữ cảnh được truy xuất hay không.
- Sự trung thành: Sự trung thực hỏi liệu mô hình có thể hiện chính xác bối cảnh đó hay không. Số liệu này quan trọng vì hệ thống có thể nghe có vẻ hợp lý nhưng vẫn trình bày sai nội dung nguồn.
Dữ liệu thử nghiệm không thực tế che giấu những thất bại thực sự
Dữ liệu thử nghiệm không thực tế là một vấn đề lớn khác. Nhiều nhóm đánh giá dựa trên các câu hỏi hoặc lời nhắc tổng hợp, rõ ràng do các nhóm nội bộ tuyển chọn cẩn thận. Điều đó về cơ bản che giấu bề mặt thất bại thực sự. Các điều kiện đánh giá trong quá trình sản xuất phải bao gồm các câu hỏi mơ hồ, tài liệu mâu thuẫn, thông tin đầu vào một phần của người dùng, nội dung cũ và các tình huống mà câu trả lời đúng là không trả lời gì cả. Nếu tập dữ liệu không phản ánh hành vi thực của người dùng thì việc đánh giá sẽ trở thành một cơ chế mang lại sự thoải mái hơn là một công cụ chẩn đoán.
Đánh giá phải tiếp tục sau khi triển khai
Việc đánh giá không nên dừng lại sau khi bạn hoàn thành lần chạy đầu tiên. RAG sản xuất thay đổi. Tài liệu thay đổi. Các phần nhúng được hoán đổi. Logic xếp hạng phát triển. Thay đổi mẫu nhắc nhở. Nếu không có đánh giá như một phần của CI/CD và theo dõi sản xuất sau khi triển khai, bạn sẽ tìm hiểu về sự hồi quy từ những người dùng không hài lòng thay vì từ sự giám sát của chính họ.
Tại sao RAG sản xuất không thành công ngay cả khi điểm chuẩn có vẻ tốt
Đây là lúc nhiều đội trở nên bối rối. Điểm chuẩn được cải thiện nhưng hệ thống trực tiếp vẫn gây thất vọng.
Thất bại trong sản xuất thường do sai lệch về khuyến khích. Các nhóm cố gắng tối ưu hóa việc thu hồi truy xuất mà không tính đến ngân sách độ trễ hoặc tối ưu hóa để có điểm LLM cao hơn mà không theo dõi độ chính xác của truy xuất. Việc truy xuất có thể bị điều chỉnh quá mức, gây ảnh hưởng đến chất lượng tạo ra, gây ra nhiễu. Việc tạo có thể bị điều chỉnh quá mức mà không quan tâm đến các cải tiến về truy xuất. Tỷ lệ thích hợp giữa độ chính xác truy xuất và độ chính xác tạo phụ thuộc vào ứng dụng. Các trường hợp sử dụng tuân thủ, pháp lý và các trường hợp sử dụng có tính rủi ro cao khác đòi hỏi độ trung thực và độ chính xác ngữ cảnh cao nhất có thể. Các trường hợp sử dụng sáng tạo có thể cho phép tiếng ồn để đổi lấy tốc độ.
Sản xuất không được tối ưu hóa trên một số liệu duy nhất. Có sự cân bằng giữa chất lượng truy xuất, độ trễ, độ mới, độ căn cứ và tính đơn giản trong vận hành. Đó là lý do tại sao thành công của bản demo có thể gây hiểu lầm đến vậy. Hệ thống khen thưởng demo “nghe có vẻ đúng”. Sản xuất khen thưởng độ tin cậy.
Cách khắc phục hệ thống RAG sản xuất
Con đường phía trước không phải là từ bỏ RAG. Đó là coi nó như một hệ thống truy xuất có kỷ luật.
PHẦN Câu hỏi thường gặp
Bạn đo lường chất lượng truy xuất trong RAG bằng cách nào?
Chúng tôi sử dụng các số liệu truy xuất như độ chính xác của ngữ cảnh, thu hồi ngữ cảnh và chất lượng xếp hạng, đồng thời kiểm tra xem bằng chứng được truy xuất có thực sự hỗ trợ việc tạo câu trả lời hay không.
Điều gì khiến hệ thống RAG bị lỗi trong quá trình sản xuất?
Lỗi sản xuất thường xảy ra nhất do sự suy giảm về chất lượng truy xuất, độ trễ tăng dần, việc nhúng/trôi kho dữ liệu và các phương pháp đánh giá kém che giấu nơi bắt đầu sự cố.
Sự trôi dạt trong đường ống RAG là gì?
Nhúng trôi dạt xảy ra khi các bản cập nhật cho mô hình nhúng, kho dữ liệu hoặc hành vi truy vấn trực tiếp thay đổi chậm hành vi truy xuất (làm giảm mức độ liên quan) mà không gây ra bất kỳ hành vi hệ thống nào bị hỏng rõ ràng.
Tại sao độ trễ RAG tăng trên quy mô lớn?
Độ trễ tăng lên vì hệ thống sản xuất thường thêm việc viết lại truy vấn, nhiều lượt truy xuất, xếp hạng lại, lệnh gọi mô hình bổ sung và kho dữ liệu lớn hơn, tất cả đều làm tăng thời gian xử lý và độ phức tạp trong vận hành.
Bạn đánh giá thế nào về tính căn cứ và trung thực trong RAG?
Bạn so sánh câu trả lời được tạo ra với bằng chứng thu được, kiểm tra xem các tuyên bố có được các nguồn hỗ trợ hay không và liệu từ ngữ có phản ánh chính xác các nguồn đó mà không bịa đặt hoặc bóp méo hay không.
Kết luận
Lỗi sản xuất trong hầu hết các hệ thống RAG không phải là kết quả của một điểm lỗi duy nhất. Thay vào đó, các kỹ sư có trách nhiệm sẽ nhận thấy hầu hết các sự cố đều bắt đầu từ một mắt xích yếu trong chuỗi được kết nối. Chất lượng truy xuất gần như luôn là lỗi đầu tiên. Các kỹ sư “giải quyết” vấn đề này bằng cách tận dụng nhiều khả năng truy xuất hơn, nhiều ngữ cảnh hơn và nhiều lớp điều phối hơn. Làm như vậy có tác dụng tăng độ trễ. Vì các phần nhúng, nội dung và hành vi của người dùng đều thay đổi theo thời gian, nên các số liệu đánh giá yếu sẽ ẩn giấu nơi hệ thống thực sự đang gặp lỗi. Người dùng bắt đầu chú ý và mất niềm tin trước khi người quản lý nhận ra có vấn đề. Đến lúc đó, sự phá vỡ của mô hình có vẻ bí ẩn. Tuy nhiên, vấn đề đã rõ ràng ngay từ đầu.
RAG thất bại ở quy mô lớn không phải vì mẫu sai mà vì việc xây dựng hệ thống RAG sản xuất đòi hỏi kỹ thuật truy xuất mạnh mẽ, quản lý độ trễ, giảm thiểu sai lệch và đánh giá liên tục. Họ yêu cầu cải thiện thứ hạng, cải thiện việc phân nhóm, khả năng quan sát tốt hơn cũng như đo lường tính căn cứ và độ trung thực. Quan trọng nhất, các nhóm cần tiếp cận RAG như một hệ thống sống chứ không phải là một kiến trúc demo cài sẵn rồi quên.
Tham khảo
- Hệ thống RAG trong sản xuất:Tại sao nó bị lỗi và cách khắc phục
- Chiến lược phân chia tốt nhất cho RAG (và LLM) vào năm 2026
- Đánh giá RAG là gì? Đo lường chất lượng truy xuất và độ tin cậy của câu trả lời
- Hướng tới việc tìm hiểu sự đánh đổi của hệ thống trong suy luận mô hình thế hệ tăng cường truy xuất
- RAGPerf:Khung đo điểm chuẩn toàn diện cho các hệ thống thế hệ tăng cường truy xuất
- Trình sắp xếp lại và truy xuất hai giai đoạn
- Từ RAG đến bối cảnh - Đánh giá cuối năm 2025 về RAG
 Tác phẩm này được cấp phép theo Giấy phép quốc tế Creative Commons Ghi công-NonCommercial-ShareAlike 4.0.
Tác phẩm này được cấp phép theo Giấy phép quốc tế Creative Commons Ghi công-NonCommercial-ShareAlike 4.0.