Trong bài viết này, chúng ta sẽ tìm hiểu về kỹ thuật duyệt web bằng cách sử dụng mô-đun lxml có sẵn trong Python.
Tìm kiếm web là gì?
Gỡ trang web được sử dụng để lấy / lấy dữ liệu từ một trang web nhờ sự trợ giúp của trình thu thập thông tin / máy quét. Gỡ bỏ trang web rất hữu ích để trích xuất dữ liệu từ một trang web không cung cấp chức năng của một API. Trong python, việc sửa lỗi web có thể được thực hiện nhờ sự trợ giúp của các mô-đun khác nhau như Beautiful Soup, Scrappy &lxml.
Ở đây chúng ta sẽ thảo luận về việc loại bỏ trang web bằng cách sử dụng mô-đun lxml.
Để làm được điều đó, trước tiên chúng ta cần cài đặt lxml .
Nhập vào dòng lệnh hoặc dấu nhắc lệnh -
>>> pip install lxml
Ở đây xpath được sử dụng để truy cập dữ liệu.
Trong bài viết này, chúng tôi sẽ trích xuất dữ liệu từ trang web được gọi là steam chứa thông tin về các trò chơi khác nhau.
https://store.steampowered.com/genre/Free%20to%20Play/
Trên trang, chúng tôi sẽ cố gắng trích xuất thông tin từ phần các bản phát hành mới phổ biến.
Ở đây chúng tôi sẽ trích xuất tên, giá, thẻ được liên kết và nền tảng mục tiêu.
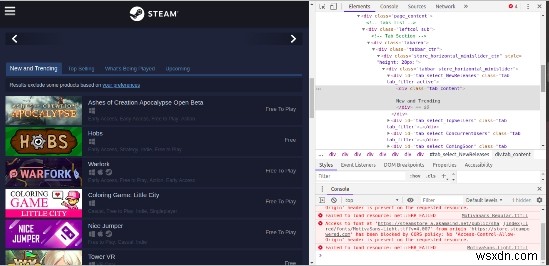
Trên trang, hãy xem mã html của tab bản phát hành mới bằng cách sử dụng tính năng phần tử kiểm tra trong chrome. Tại đây, chúng ta sẽ biết rằng thẻ nào đang lưu trữ thông tin bắt buộc.
Đây trong trang web này; mọi phần tử danh sách đều được đóng gói trong thẻ div id =tab_content được đóng gói thêm trong
a div tag id=tab_select_newreleases
Bây giờ chúng ta hãy xem việc triển khai